
티스토리 뷰
운영체제 서비스
운영체제는 그 속에서 프로그램이 실행될수 있도록 하는 환경을 제공합니다. 다양한 운영체제는 여러 노선에 따라 구성되며, 구조는 각각 다릅니다. 하지만 공통된 부류가 있습니다.

💡 사용자 인터페이스: User Interface
- 거의 모든 운영체제는 사용자 인터페이스를 제공합니다. 그래픽 사용자 인터페이스(GUI), 터치 스크린 인터페이스, 명령어 라인 인터페이스(CLI)등이 있습니다.
💡 프로그램 수행: program execution
- 시스템은 프로그램을 메모리에 적재해 그 프로그램이 정상적이든 비정상적이든 실행할 수 있어야 합니다.
💡 입출력 연산: I/O operation
- 수행중인 프로그램은 입출력을 요구할 수 있으며, 효율과 보안 및 보호를 위해 사용자들은 통상 입출력 장치를 직접 제어할 수 없습니다. 따라서 운영체제가 입출력의 수단을 제공해야 합니다.
💡 파일 시스템 조작: file system manipulation
- 프로그램은 이름에 의해 파일을 생성하고 삭제할 수 있고 열람하고 기타 등등의 기능을 할 수 있어야합니다. 몇몇 프로그램은 파일 소유권에 따라 권한을 확인해야하며, 권한에 따라 접근 범위를 지정해야합니다.
💡 통신: communication
- 한 프로세스가 다른 프로세스와 정보를 교환해야 할 상황이 있을 수 있습니다. 이러한 통신에는 두 가지 중요한 방법이 있는데 첫번째 방법은 동일한 컴퓨터에서 수행되고 있는 프로세스들 사이에서 일어나는 것이고, 두번째는 네트워크에 의해 함께 묶여 서로 다른 컴퓨터 시스템상에서 수행되는 프로세스들 사이에서 일어납니다.
- 통신은 공유 메모리를 통해서 구현될 수 있고, 메시지 전달(네트워크 패킷)기법을 사용하여 구현될 수 있습니다.
💡 오류 탐지: error detection
- 운영체제는 모든 가능한 오류를 항상 의식하고 있어야 합니다. 운영체제는 올바르고 일관성 있는 계산을 보장하기 위해 각 유형의 오류에 대해 적당한 조치를 해야합니다.
💡 자원 할당: resource allocation
- 다수의 프로세스나 다수의 작업이 동시에 실행될 때 그들 각각에 자원을 할당해주어야 합니다.
💡 기록 작성: logging
- 우리는 어떤 프로그램이 어떤 종류릐 컴퓨터 자원을 얼마나 많이 사용되었고, 사용중인지 추적할 수 있길 바랍니다.
💡 보호와 보안: protection, security
- 다중 사용자 컴퓨터 시스템 또는 네트워크로 연결된 컴퓨터 시스템에 저장된 정보의 소유자는 그 정보의 사용을 통제하길 원합니다.
또한 서로 다른 여러 프로세스가 병행하게 수행될 때, 한 프로세스가 다른 프로세스나 운영체제를 방해하면 안됩니다. 보호는 시스템 자원에 대한 모든 접근이 통제되도록 보장하는 것을 필요로 합니다. 또한 외부로부터의 시스템 보안 또한 중요합니다.
사용자와 운영체제 인터페이스
사용자가 운영체제와 접촉하는 방식에는 CLI, GUI, TSI등이 있습니다. 하지만 CLI에 대해서만 알아봅니다.
💡 명령 인터프리터
- 명령어 라인 인터페이스(CLI) 또는 명령 인터프리터라고 합니다.
- 중요한 기능은 사용자가 지정한 명령을 가져와 그것을 수행하는 것입니다. 이 수준에서 제공된 많은 명령은 파일을 조작합니다. 보통 두 가지 일반적인 방식으로 구현될 수 있다고 합니다.
- 첫째, 명령 인터프리터 자체가 명령을 실행할 코드를 가지는 경우입니다. 예를들어 rm file.txt 라는 명령어를 입력하면 명령 인터프리터가 자신의 코드의 한 부분으로 분기하고, 그 코드 부분이 매개변수를 설정하고 적절한 시스템 콜을 합니다. 이 경우 제공될 수 있는 명령의 수가 명령 인터프리터의 크기를 결정하게 되는데 그 이유는 각 명령이 자신의 구현 코드를 요구하기 때문입니다.
- 둘째, 시스템 프로그램에 의해 대부분의 명령을 구현하는 것입니다. 이러한 경우 명령 인터프리터는 해당 명령어를 전혀 알지 못합니다. 단지 메모리에 적재되어 실행될 파일을 식별하기 위해 명령을 사용합니다. 예를들어 rm file.txt 라는 명령어를 입력하면 rm 이라는 파일을 찾아서 메모리에 적재하고 매개변수 file.txt를 수행합니다. rm 명령과 관련된 로직은 rm 이라는 파일 내의 코드로 완전하게 정의되어있습니다.
시스템 콜
시스템 콜은 운영체제에 의해 사용 가능하게 된 서비스에 대한 인터페이스를 제공합니다. 또한 시스템 콜은 사용되는 컴퓨터에 따라 다른 방법으로 발생합니다.
운영체제가 어떻게 시스템 콜을 사용할 수 있게 만드는지에 대해 논의하기 전에 어떻게 사용되는지 알아봅시다.

💡 응용 프로그래밍 인터페이스
- 단지 cp in.txt out.txt 라는 간단한 명령어를 입력했을 뿐인데 그 사이 엄청나게 많은 시스템 콜을 수행하게 됩니다. 이러한 과정이 있다는 사실을 오늘 처음 알게 되었습니다.
- 대부분의 응용 프로그램 개발자들은 응용 프로그래밍 인터페이스에 따라 프로그램을 설계합니다. API는 각 함수에 전달되어야 할 매개변수들과 프로그래머가 기대할 수 있는 반환 값을 포함하여 응용 프로그래머가 사용 가능한 함수의 집합을 명시합니다.
- 자바는 자바 가상 기계에서 실행될 수 있는 프로그램을 위한 Java API가 있습니다. 프로그래머는 운영체제가 제공하는 코드의 라이브러리를 통해 API를 활용합니다.
- 프로그래머는 왜 시스템 콜을 바로 호출하는 것보다 API에 따라 프로그래밍하는 것을 선호하는가? 그에 대한 답은 프로그램 호환성과 관련 있다고 합니다. 우리는 우리가 만든 프로그램이 어느 시스템에서든 컴파일되고 실행되길 원합니다. 그리고 시스템 콜은 종종 더 자세한 명세가 필요하고 프로그램상에서 작업하기가 어렵습니다. 그럼에도 불구하고 API 함수를 호출하는 것과 커널의 관련된 시스템 콜을 호출하는 것에는 강한 상관관계가 존재한다고 합니다.
실행시간 환경(RTE)
- RTE는 운영체제가 제공하는 시스템 콜에 대한 연결고리 역할을 하는 시스템 콜 인터페이스를 제공합니다. 이 시스템 콜 인터페이스는 API 함수의 호출을 가로채어 필요한 운영체제 시스템 콜을 호출한다. 보통 각 시스템 콜에는 번호가 할당되고 시스템 콜 인터페이스는 이 번호에 따라 색인되는 테이블을 유지합니다. 시스템 콜 인터페이스는 의도하는 시스템 콜을 호출하고 시스템 콜의 상태와 반환값을 돌려줍니다.
- RTE가 있으므로 응용 프로그램 개발자는 호출된 시스템 콜이 어떻게 구현되고, 실행 중 무슨 작업을 어떻게 하는지 아무것도 알 필요가 없습니다. 단지 API를 잘 준수하고 시스템 콜의 결과로서 운영체제가 무엇을 할것인지 이해만 하면 됩니다.

운영체제에 매개변수를 전달하기 위한 방법
- 가장 간단한 방법은 매개변수를 레지스터 내에 전달하는 방법입니다. 그러나 어떤 경우 레지스터보다 더 많은 매개변수가 있을 수 있습니다.
- 매개변수가 많은 경우 매개변수는 메모리의 블록이나 테이블에 저장되고, 블록의 주소가 레지스터 내에 매개변수로 전달됩니다. Linux는 이러한 접근법을 조합하여 사용하는데, 매개변수가 5개 이하인 경우 레지스터가 사용됩니다. 반면 매개변수의 개수가 5개를 넘으면 블록 방법이 사용됩니다. 매개변수는 프로그램에 의해 스택에 넣어질 수 있고, 운영체제에 의해 꺼내집니다. 일부 운영체제는 블록이나 스택 방법을 선호하는데 이들 접근법은 전달되는 매개변수의 길이나 개수를 제한하지 않기 때1문입니다.
💡 시스템 콜의 유형
프로세스 제어
- 실행 중인 프로그램은 수행을 정상적으로든 비정상적으로든 멈출수 있어야 합니다. 만약 현재 실행 중인 프로그램이 비정상적으로 중지하기 위해 시스템 콜을 호출되거나 프로그램에 문제가 발생해 오류 트랩(trap)을 유발할 경우 때때로 메모리 덤프가 이루어지고, 오류 메시지가 생성됩니다.
- 다중 태스킹 시스템에서 둘 이상의 프로세스들은 빈번하게 데이터를 공유합니다. 공유되는 데이터의 일관성을 보장하기 위해 운영체제는 프로세스가 공유 데이터를 잠금 수 있는 시스템 콜을 제공합니다. 그러면 잠금이 해제될 때까지 다른 프로세스들은 접근할 수 없게 됩니다. 이런 시스템은 acquire_lock, release_lock 시스템 콜을 제공합니다.
파일 제어
- 파일을 생성(create)하고 삭제(delete)할 수 있어야 합니다. 이들 시스템 콜은 파일 이름이나 파일 속성의 일부를 요구합니다. 파일이 생성되면 파일을 열고(open) 기타 등등의 기능을 할 수 있습니다.
- 파일 시스템이 파일을 조직화하기 위해 디렉토리 구조를 가진다면 해당 디렉토리에 대해서도 연산 집합이 필요합니다.
장치 관리
- 프로세스는 작업을 계속 수행하기 위해 추가 자원이 필요할 수 있습니다. 이러한 추가 자원은 주 기억장치, 디스크 드라이브 등이 될 수 있습니다. 만약 자원들을 사용할 수 있다면 자원이 주어지고, 제어가 사용자 프로그램으로 복귀돌 수 있지만 그렇지 않다면 자원을 사용하게 될 때까지 기다려야 합니다.
정보 유지 관리
- 사용자 프로그램과 운영체제 간의 정보 전달을 위해 존재합니다.
- 운영체제는 현재 운영되고 있는 모든 프로세스에 관한 정보를 가지고 있으며, 이러한 정보에 접근하기 위한 시스템 콜이 있습니다.
통신
- 통신 모델에는 메시지 전달(네트워크 패킷)과 공유 메모리 두 가지 일반적인 모델이 있습니다.
- 메시지 전달에서는 통신하는 두 프로세스가 정보를 교환하기 위해 서로 메시지를 주고 받습니다. 이러한 메시지는 두 프로세스 사이에 직접적으로 교환되거나 네트워크를 통하여 간접적으로 교환할 수 있습니다.
- 공유 메모리 모델에서는 프로세스가 다른 프로세스가 소유한 메모리에 접근을 하기 위해 shared_memory_create, shared_memory_attach 시스템 콜을 사용합니다. 정상적으로 운영체제는 한 프로세스가 다른 프로세스의 메모리에 접근하는 것을 막으려고 하지만 공유 메모리는 두 개 이상의 프로세스가 이러한 제한을 제가하는데 동의할 것을 필요로 합니다. 그런 후 이 프로세스들은 공유 영역에서 데이터를 읽고 씀으로써 정보를 교환할 수 있습니다.
- 데이터 형식은 운영체제의 제어하에 있는게 아닌 이들 프로세스에 의해 결정됩니다. 프로세스는 또한 동일한 위치에 동시에 쓰지 않도록 보장할 책임을 집니다.
보호
- 보호는 컴퓨터 시스템이 제공하는 자원에 대한 접근을 제어하기 위한 기법을 지원합니다.
링커와 로더
일반적으로 프로그램은 디스크에 이진 실행 파일(xxx.out, 또는 prog.exe)로 존재합니다. CPU에서 실행하려면 프로그램을 메모리로 가져와 프로세스 형태로 배치되어야 합니다.
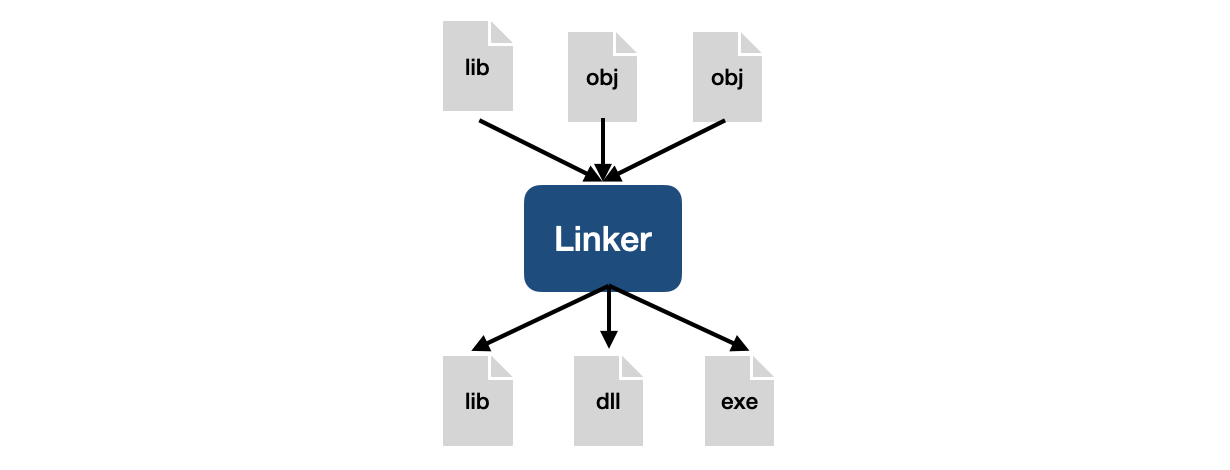
💡 링커란
- 링커는 컴파일러에서 생성한 개체 파일이나 라이브러리를 결합하여 실행 가능한 프로그램이나 라이브러리를 만드는 프로그램입니다.
- 링커는 프로그램에 사용된 모든 함수나 변수가 해당 정의에 맞는지 확인되도록 서로 다른 개체 파일과 라이브러리 간의 참조를 확인합니다.
- 프로그램이 컴파일되면 일반적으로 각각 특정 모듈이나 소스 파일에 대한 컴파일된 코드를 포함하는 별도의 개체 파일로 나뉩니다. 이러한 개체 파일에는 다른 모듈에 정의된 외부 함수 및 변수에 대한 참조가 포함되어 있습니다. 링커는 라이브러리 또는 개체 파일에서 올바른 정의를 찾고 올바른 메모리 위치를 가리키도록 프로그램의 참조를 수정하여 이러한 참조를 해결합니다.
💡 로더란
- 로더는 이진 실행 파일을 메모리에 적재하는데 사용되며, CPU 코어에서 실행할 수 있는 상태가 됩니다.
로더의 기능(순서로 나열)
- 할당 - 프로그램을 메모리에 할당하기 위해 로더는 프로그램의 크기에 따라 메모리를 할당합니다. 즉 프로그램 실행을 위해 메인 메모리에 공간을 확보하는 기능입니다.
- 연결 - 두 개 이상의 개별 개체 프로그램 또는 모듈을 결합하고 필요한 정보를 제공합니다.
- 재배치 - 실행시키고자하는 프로그램을 해당 위치와 다른 주소에서 로드할 수 있도록 수정합니다.(매핑)
- 적재 - 실행을 위해 프로그램을 할당된 메인 메모리에 실제로 옮기는 기능입니다.
로더의 종류
- Compile And Go Loader
- 컴파일러가 로더의 기능까지 수행합니다. 단 연결의 기능은 수행하지 않습니다.
- 절대 로더
- 목적 프로그램을 메인 메모리에 적재시키는 기능만 수행하는 로더로, 로더 중 가장 간단한 프로그램으로 구성되어 있습니다.
- 기억 장소 할당이나 연결을 프로그래머가 직접 지정하며 한번 지정한 메인 메모리의 위치는 변경하기 어렵습니다.
- 직접 연결 로더
- 일반적인 기능의 로더로 로더의 기본 기능 네 가지를 모두 수행하는 로더입니다.
- 재배치 로더, 상대 로더라고도 합니다.
- 동적 적재 로더
- 프로그램을 한번에 적재하는게 아닌 실행 시에 필요한 부분만 적재하고 나머지는 보조 기억 장치에 저장해두는 것으로 호출 시 적재라고도 합니다.
운영체제 구조
💡 모놀리식 구조
- 모놀리식 구조는 구조가 없습니다. 커널의 모든 기능을 단일 주소 공간에서 실행되는 단일 정적 이진 파일에 넣는 것 입니다.
- 커널과 시스템 프로그램 두 부분으로 구성됩니다.

장점
- 하나의 구조이므로 오버헤드가 거의 없고 커널 내 통신 속도가 빠릅니다.
- 배포하기 쉽습니다.
단점
- 구현 및 확장이 어렵습니다.
- 하나를 수정하면 배포 시 전부 다 배포해야합니다.
- 시스템의 한 부분을 변경하게 된다면 다른 부분에 영향을 줄 수 있는 확률이 높습니다.
- 디버깅하기 어렵습니다.
💡 계층적 접근
- 계층적 접근 방식은 운영체제가 여러 개의 층으로 나누어집니다. 최하위 층은(층 0) 하드웨어이고 최상위 층은 사용자 인터페이스입니다.
- 각 층은 자신보다 하위 수준의 층에 의해 제공된 연산들만 사용해 구현합니다. 한 층은 이러한 연산들이 어떻게 구현되는지 알 필요가 없고 단지 무엇을 하는지만 알면됩니다.

장점
- 각각의 층들은 자신의 역할들만 수행하므로 구현과 디버깅이 쉽습니다.
- 캡슐화를 할 수 있습니다.
단점
- 각 계층의 정의나 접근 방식을 적절하게 정의해야 합니다.
- 만약 접근해야하는 계층의 깊이가 깊을 경우 여러 계층을 통과해야하기 때문에 오버헤드가 발생하게 됩니다.
💡 마이크로 커널
- 모놀리식 구조를 가진 UNIX가 시간이 지남에따라 확장이되고 관리가 힘들어졌습니다.
- 이러한 마이크로 커널은 모든 중요하지 않은 구성요소를 커널로부터 제거하고, 그것들을 별도의 메모리 주소 공간에 존재하는 사용자 수준 프로그램으로 구현하여 운영체제를 구성하는 방법입니다.
- 클라이언트 프로그램이 파일에 접근하길 원한다면, 파일 서버와 반드시 상호 작용을 해야합니다. 클라이언트 프로그램과 서비스는
직접 상호 작용을 하지 않고 오직 마이크로 커널과 메시지를 교환함으로써 간접적으로 상호 작용합니다.

장점
- 커널의 크기가 줄어 안정성이 높습니다.
- 대부분의 새로운 서비스는 사용자 공간에 추가되므로 운영체제의 기능 확장에 좋습니다.
- 마이크로 커널은 서비스 대부분이 커널이 아닌 사용자 프로세스에서 수행되므로 높은 보안성과 신뢰성을 제공합니다.
- 한 서비스가 잘못되더라도 운영체제의 다른 부분은 영향을 미치지 않습니다.
단점
- 가중된 스스템 기능 오버레드로 인해 성능이 안좋아집니다.
- 두 개의 사용자 수준 서비스가 통신해야 하는 경우 별도의 주소 공간에 서비스가 존재하기 때문에 메시지가 복사되어야 하는데,
운영체제가 메시지를 교환하기 위해 한 프로세스에서 다음 프로세스로 전환해야 할 수도 있습니다. 즉 메시지 복사 및 프로세스 전환 관련된 오버헤드가 발생하여 성능 저하를 일으킴
💡 모듈
- 대부분의 현대 운영체제는 적재가능 커널 모듈(LKM)을 구현합니다.
- 코어 커널은 핵심 모듈로 구성되어 있으며, 부팅이나 실행 시에 부가적인 서비스들을 동적으로 연결합니다.
- 각 모듈은 정해진 인터페이스를 통해 다른 모듈과 의사소통합니다.
- 각 모듈은 커널내에 필요에 따라 적재가능합니다.
- 각 모듈은 인터페이스를 통해 다른 모듈과 의사소통한다는 점에서 계층적 접근 구조를 닮았습니다. 그러나 모듈에서 다른 모듈을 호출할 수 있다는 점에서는 계층적 접근 구조보다는 유연합니다.
- 코어 모듈은 핵심 기능만 가지고 있고, 다른 모듈들과 어떻게 통신할지 알고 있다는 점에서는 마이크로 커널 구조와 비슷합니다. 하지만 메시지를 사용하지 않으므로 보다 효율적입니다.

장점
- 필요에 따라 모듈을 추가하거나 제거할 수 있으므로 확장성이 좋고 유지보수하기 쉽습니다.
- 모듈은 독립적으로 있기 때문에 유연하고 추후 요구사항 반영이나 변화에 쉽게 대응할 수 있습니다.
- 독립적으로 존재하기 때문에 테스트 및 디버깅이 쉽습니다.
단점
- 설계시 시스템 전반적인 아키텍처를 고려해야하므로 복잡성이 증가할 수 있습니다.
- 각각의 모듈간 통신이 필요하므로 오버헤드가 발생하여 성능이 저하될 수 있습니다.
- 이러한 오버헤드 및 복잡한 아키텍처로 인해 런닝 커브가 발생할 수 있습니다.
참고자료
- https://www.geeksforgeeks.org/basic-functions-of-loader/
- 운영체제 2장. 운영체제 구조
- Total
- Today
- Yesterday
- spring boot redisson destributed lock
- spring boot excel download oom
- 트랜잭셔널 아웃박스 패턴 스프링부트
- transactional outbox pattern
- transactional outbox pattern spring boot
- redis 대기열 구현
- space based architecture
- 공간 기반 아키텍처
- service based architecture
- spring boot excel download paging
- redis sorted set
- spring boot poi excel download
- spring boot 엑셀 다운로드
- 자바 백엔드 개발자 추천 도서
- @ControllerAdvice
- 트랜잭셔널 아웃박스 패턴 스프링 부트 예제
- 람다 표현식
- pipeline architecture
- java ThreadLocal
- 서비스 기반 아키텍처
- spring boot redis 대기열 구현
- redis sorted set으로 대기열 구현
- pipe and filter architecture
- spring boot redisson sorted set
- JDK Dynamic Proxy와 CGLIB의 차이
- java userThread와 DaemonThread
- polling publisher spring boot
- 레이어드 아키텍처란
- microkernel architecture
- spring boot redisson 분산락 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |