
티스토리 뷰
728x90
반응형
LinkedHashSet
- Linked HashSet은 HashSet과는 다르게 입력 순서를 보장해줍니다.
- Linked HashSet은 입력 순서를 보장하기 위해 Linked List처럼 이전 노드를 가리키는 변수와 다음 노드를 가리키는 변수를 가지고 있습니다. 이를 통해 순서를 보장하고 있습니다.
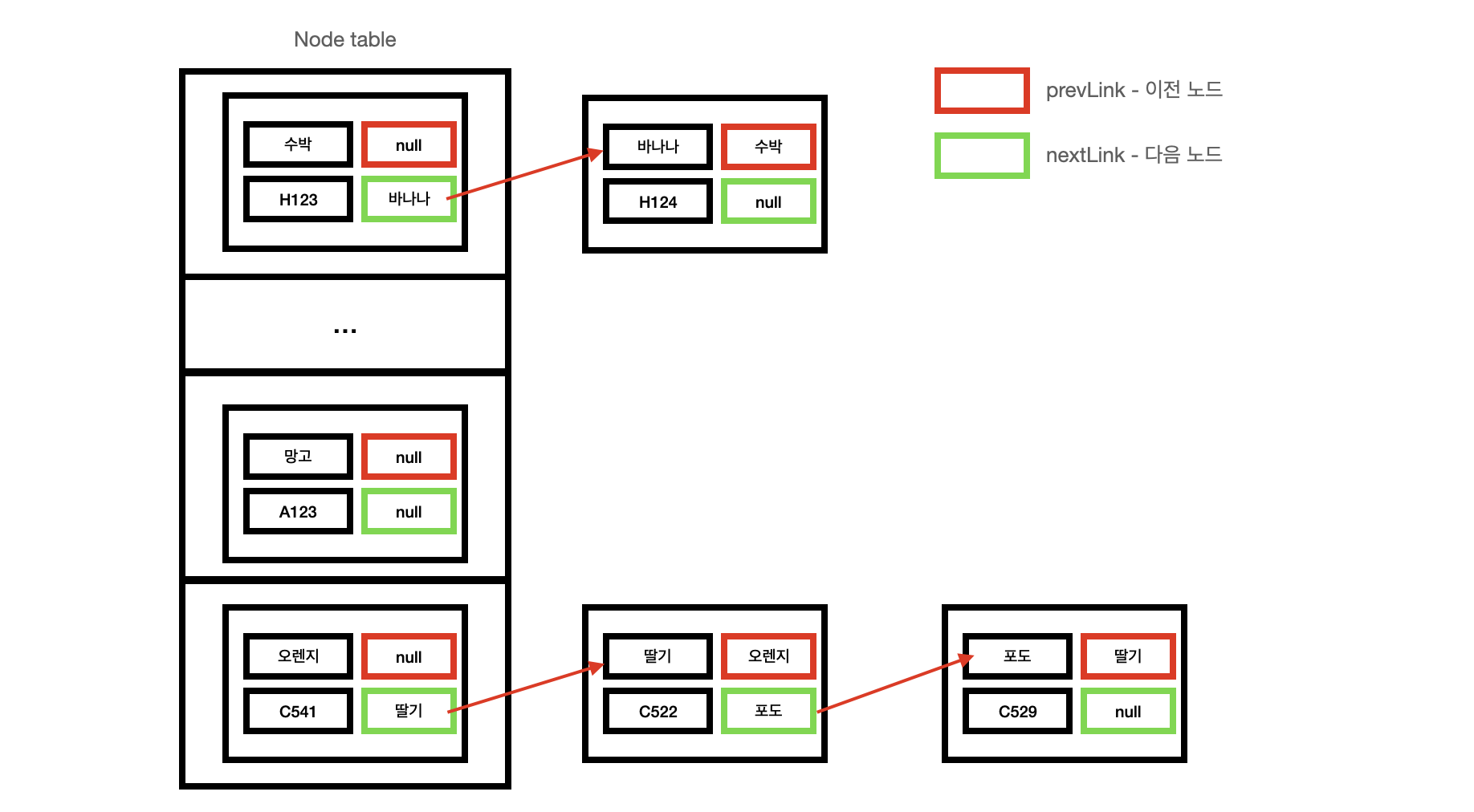
💡 Node의 구조

LinkedHashSet 구현
💡 구현하고자 하는 메서드
public interface Set<E> {
/**
* 데이터가 Set에 없는 경우 데이터를 추가합니다.
*/
void add(E element);
/**
* 특정 데이터를 Set에서 삭제합니다.
*/
void remove(E element);
/**
* 특정 데이터가 포함되어 있는지 확인합니다.
*/
boolean contains(E element);
/**
* 특정 데이터가 현재 집합과 같은지 여부를 확인합니다.
*/
boolean equals(Object o);
/**
* 현재 Set의 모든 데이터를 삭제합니다.
*/
void clear();
}
💡 Node 구현
- Node는 아래와 같은 변수들을 가지고 있습니다.
public class Node<E> {
final int hash; // 해시값
final E key; // 데이터
Node<E> prevLink; // 이전 노드의 링크
Node<E> nextLink; // 다음 노드의 링크
public Node(int hash, E key, Node<E> nextLink) {
this.hash = hash;
this.key = key;
this.prevLink = null;
this.nextLink = nextLink;
}
}
💡 LinkedHashSet의 기본 변수와 보조해시 함수
- HashSet과의 차이점은 노드의 가장 첫 부분을 나타내는 head 변수와 가장 마지막 부분을 나타내는 tail 변수를 가지고 있습니다.
- 해시충돌을 조금이라도 더 피하기 위해 보조해시 함수인 hash 메서드를 가지고 있습니다. 이 메서드에서 음수를 반환할 수 있으므로 Math.abs메서드를 사용하고 있습니다.
public class LinkedHashSet<E> implements Set<E> {
private static final int DEFAULT_CAPACITY = 16;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private int size; // 노드의 총 개수
private Node<E>[] tables; // 노드를 저장할 배열
private Node<E> head; // 노드의 가장 첫 부분
private Node<E> tail; // 노드의 가장 마지막 부분
public LinkedHashSet() {
this.tables = (Node<E>[]) new Node[DEFAULT_CAPACITY];
this.size = 0;
this.head = null;
this.tail = null;
}
private static final int hash(Object key) {
int hash;
if (key == null) {
return 0;
} else {
return Math.abs(hash = key.hashCode()) ^ (hash >>> 16);
}
}
}
💡 add 메서드
- add 메서드는 HashSet의 add 메서드와 비슷합니다. 다만 차이점으로는 해시 충돌이 발생하는 경우 충돌한 노드의 마지막에 새로운 노드를 추가할 수 있도록 해주어야 합니다. 이때 노드의 prevLink와 nextLink를 사용하여 서로 연결을 이어줍니다.
- appendToLastLink는 추가하고자하는 노드를 마지막(tail)에 붙여주기 위함입니다.
@Override
public void add(E element) {
add(hash(element), element);
}
private void appendToLastLink(Node<E> o) {
Node<E> last = this.tail;
this.tail = o;
if (last == null) {
this.head = o;
} else {
last.nextLink = o;
o.prevLink = last;
}
}
private void add(int hash, E element) {
int index = hash % this.tables.length;
Node<E> newNode = new Node<>(hash, element, null);
// 해시 충돌이 발생하지 않은 경우
if (this.tables[index] == null) {
this.tables[index] = newNode;
} else {
// 해시 충돌이 발생한 경우
Node<E> conflictNode = this.tables[index];
Node<E> prev = null;
while (conflictNode != null) {
// 중복되는 요소라면 return
if ((conflictNode.hash == hash) && (conflictNode.key == element) && (conflictNode.key.equals(element))) {
return;
}
prev = conflictNode; // 이전 노드 기억
conflictNode = conflictNode.nextLink; // 다음노드로 이동
}
prev.nextLink = newNode;
}
this.size++;
appendToLastLink(newNode);
if (size >= DEFAULT_LOAD_FACTOR * tables.length) {
resize();
}
}
add 테스트
- TEST 1 ~ TEST 5까지는 해시 충돌이 발생하지 않기 때문에 tabls에 차곡차곡 담게됩니다. 하지만 0-42L, 0-43-은 해시가 같기 때문에 해시충돌이 발생하게 됩니다. 이때 0-42L의 nextLink는 0-43-이 되고 0-43-의 prevLink는 0-42L이 됩니다.
public class Main {
public static void main(String[] args) {
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("TEST 1");
linkedHashSet.add("TEST 2");
linkedHashSet.add("TEST 3");
linkedHashSet.add("TEST 4");
linkedHashSet.add("TEST 5");
linkedHashSet.add("0-42L");
linkedHashSet.add("0-43-"); // 해시 충돌 발생 0-42L와 해시 같음
linkedHashSet.print();
// TEST 1 -> TEST 2 -> TEST 3 -> TEST 4 -> TEST 5 -> 0-42L -> 0-43
}
}
💡 resize 메서드
- resize 메서드는 HashSet에서 배운 내용과 동일합니다.
private void resize() {
int newCapacity = this.tables.length * 2;
final Node<E>[] newTable = (Node<E>[]) new Node[newCapacity];
for (int i = 0; i < tables.length; i++) {
Node<E> node = tables[i];
if (node == null)
tables[i] = null; // help gc
Node<E> nextNode;
while (node != null) {
int index = node.hash % newCapacity;
// 해시 충돌이 발생한 경우
if (newTable[index] != null) {
Node<E> tail = newTable[index];
while (tail != null) {
tail = tail.nextLink;
}
node.nextLink = null;
tail.nextLink = node;
} else {
// 해시 충돌이 발생하지 않은 경우
node.nextLink = null;
newTable[index] = node;
}
nextNode = node.nextLink;
node.nextLink = null;
node = nextNode;
}
}
this.tables = null;
this.tables = newTable;
}
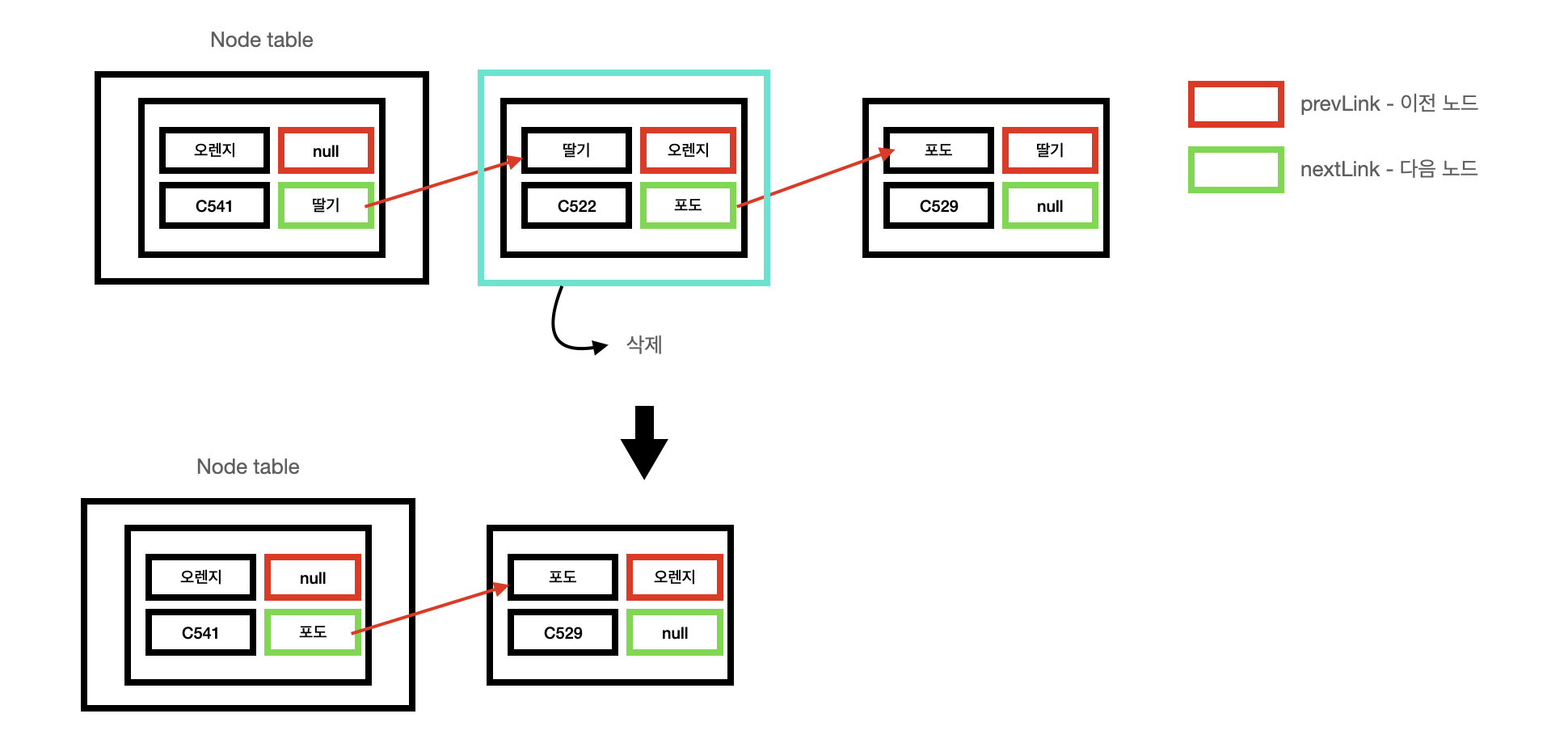
💡 remove 메서드
private void unlinkNode(Node<E> removedNode) {
Node<E> prevNode = removedNode.prevLink; // 삭제할 노드의 이전 노드
Node<E> nextNode = removedNode.nextLink; // 삭제할 노드의 다음 노드
// 이전 노드가 없다면 삭제할 노드의 다음 노드가 head가 됩니다.
if (prevNode == null) {
this.head = nextNode;
} else {
// 이전 노드가 존재한다면 이전 노드의 다음 노드에 삭제할 노드의 다음 노드를 연결시켜줍니다.
// 삭제할 노드의 이전 노드의 참조를 명시적으로 끊어줍니다.
prevNode.nextLink = nextNode;
removedNode.prevLink = null;
}
// 다음 노드가 없다면 이전 노드가 tail이 됩니다.
if (nextNode == null) {
this.tail = prevNode;
} else {
// 다음 노드가 존재한다면 다음 노드의 이전 노드에 삭제할 노드의 이전 노드를 연결시켜줍니다.
// 삭제할 노드의 다음 노드의 참조를 명시적으로 끊어줍니다.
nextNode.prevLink = prevNode;
removedNode.nextLink = null;
}
}
@Override
public void remove(E element) {
int hash = hash(element);
int index = hash % tables.length;
Node<E> node = tables[index];
Node<E> prevNode = null;
if (node == null) {
return;
}
while (node != null) {
// 삭제하고자하는 데이터를 찾았다면
if ((node.hash == hash) && (node.key == element) && (node.key.equals(element))) {
Node<E> removedNode = node; // 삭제할 노드
// 삭제할 노드의 이전 노드가 없다면 삭제할 노드의 다음 노드가 tables의 index에 위치하게 됩니다.
if (prevNode == null) {
tables[index] = removedNode.nextLink;
} else {
// 이전 노드의 다음 노드에 삭제할 노드의 다음 노드를 연결시켜줍니다.
prevNode.nextLink = removedNode.nextLink;
}
unlinkNode(removedNode);
removedNode = null;
size--;
break;
}
prevNode = node;
node = node.nextLink;
}
}
💡 contains 메서드
- contains 메서드는 요소를 받아 요소의 해시값을 구한뒤 테이블에서 요소가 위치한 인덱스를 탐색한 후, 해시 충돌이 발생하여 연결 리스트 구조로 되어 있을 수 있으니 while문을 통해 마지막 노드까지 탐색해줍니다. 이때 while문을 순회하면서 요소가 같은지 판별 후 같다면 true를 그렇지 않으면 최종적으로 false를 반환하게 됩니다.
@Override
public boolean contains(E element) {
int index = hash(element) % tables.length;
Node<E> node = tables[index];
while (node != null) {
if ((element == node.key) || (element != null && node.key.equals(element))) {
return true;
}
node = node.nextLink;
}
return false;
}
💡 equals 메서드
@Override
public boolean equals(Object obj) {
if (obj == this) return true;
if (!(obj instanceof LinkedHashSet)) return false;
try {
LinkedHashSet<E> oSet = (LinkedHashSet<E>) obj;
if (oSet.size != size) return false;
for (int i = 0; i < oSet.tables.length; i++) {
Node<E> oTable = oSet.tables[i];
while (oTable != null) {
if (!contains((E) oTable)) {
return false;
}
oTable = oTable.nextLink;
}
}
} catch (ClassCastException e) {
return false;
}
return true;
}
💡 clear 메서드
- clear 메서드는 LinkedHashSet이 가지고 있는 모든 요소를 지웁니다.
- 해시 충돌이 발생할 수 있기 때문에 node.nextLink까지 명시적으로 GC처리를 해주어야 하는게 아닌가 싶습니다.
@Override
public void clear() {
for (int i = 0; i < tables.length; i++) {
Node<E> node = tables[i];
Node<E> nextNode;
while (node != null) {
nextNode = node;
node = null; // help gc
node = nextNode.nextLink;
}
tables[i] = null;
}
this.size = 0;
this.head = null;
this.tail = null;
}
Linked HashSet의 시간 복잡도
💡 탐색
- 일반적으로 O(1) 만큼의 시간복잡도를 가지게 되며, 이또한 해시충돌이 빈번히 발생하는 경우 조금 더 걸리지 않을까? 생각합니다.
💡 추가
- 일반적으로 O(1) 만큼의 시간복잡도를 가지고 해시충돌이 빈번히 발생하는 경우 마지막 노드의 다음 노드에 추가되어야 하므로 이때 O(1) 보다는 시간이 조금 더 걸릴거 같습니다.
💡 삭제
- 일반적으로 O(1) 만큼의 시간복잡도를 가지게 되며, 이또한 해시충돌이 빈번히 발생하는 경우 조금 더 걸리지 않을까? 생각합니다.
✔️ 정리
- LinkedHashSet은 HashSet과 비슷한 부분이 많으며 LinkedList의 head와 tail부분이 추가적으로 있습니다.
- 공부를 하며 쓴글이므로 정확하지 않을 수 있습니다.
깃 허브)
참고자료)
728x90
반응형
'자료구조' 카테고리의 다른 글
| 자료구조 - Hash Set (0) | 2022.12.07 |
|---|---|
| 자료구조 - Array List (0) | 2022.12.04 |
| 자료구조 - Doubly Linked List (0) | 2022.12.03 |
| 자료구조 - Singly Linked List (0) | 2022.12.02 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- @ControllerAdvice
- spring boot excel download oom
- 공간 기반 아키텍처
- spring boot redis 대기열 구현
- spring boot excel download paging
- microkernel architecture
- space based architecture
- JDK Dynamic Proxy와 CGLIB의 차이
- service based architecture
- java userThread와 DaemonThread
- spring boot redisson destributed lock
- spring boot 엑셀 다운로드
- 자바 백엔드 개발자 추천 도서
- 람다 표현식
- pipeline architecture
- transactional outbox pattern
- spring boot redisson sorted set
- 트랜잭셔널 아웃박스 패턴 스프링 부트 예제
- redis 대기열 구현
- redis sorted set
- java ThreadLocal
- spring boot redisson 분산락 구현
- pipe and filter architecture
- polling publisher spring boot
- transactional outbox pattern spring boot
- redis sorted set으로 대기열 구현
- 레이어드 아키텍처란
- 서비스 기반 아키텍처
- spring boot poi excel download
- 트랜잭셔널 아웃박스 패턴 스프링부트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
글 보관함